「教育データ標準」について考える駄文の続きです。(前回)
文部科学省が取り組んでいる「教育データ標準」という取り組みは,サービス提供者や使用者が「相互に交換,蓄積,分析が可能となるように収集するデータの意味を揃えること」を目的としています。
「データの意味を揃える」というのは,たとえば,アンケート質問に対する選択肢を統一するような試みのことです。
「職業」の選択肢を用意するとき,「学生/社会人/…」とするか,「小・中学生/高校生/大学生/サラリーマン/自営業/…」とするか。これがバラバラだと調査結果の比較が面倒になるのと同じで,教育データも記録するデータの意味を揃えないと交換,蓄積,分析で面倒が生ずるというわけです。こういうのを「データの桁を揃える」みたいに表現することもあります。
ちなみに,心理学における心理測定(心理アンケート調査)の世界では「尺度集」というものが蓄積されており,これを共有することで,別々に実施された測定結果を比較検討できるような文化があります。いろんなジャンルのものがありますが,子どもの発達に関係するものを集めた『心理測定尺度集IV 子どもの発達を支える〈対人関係・適応〉』(サイエンス社)は有名です。
—
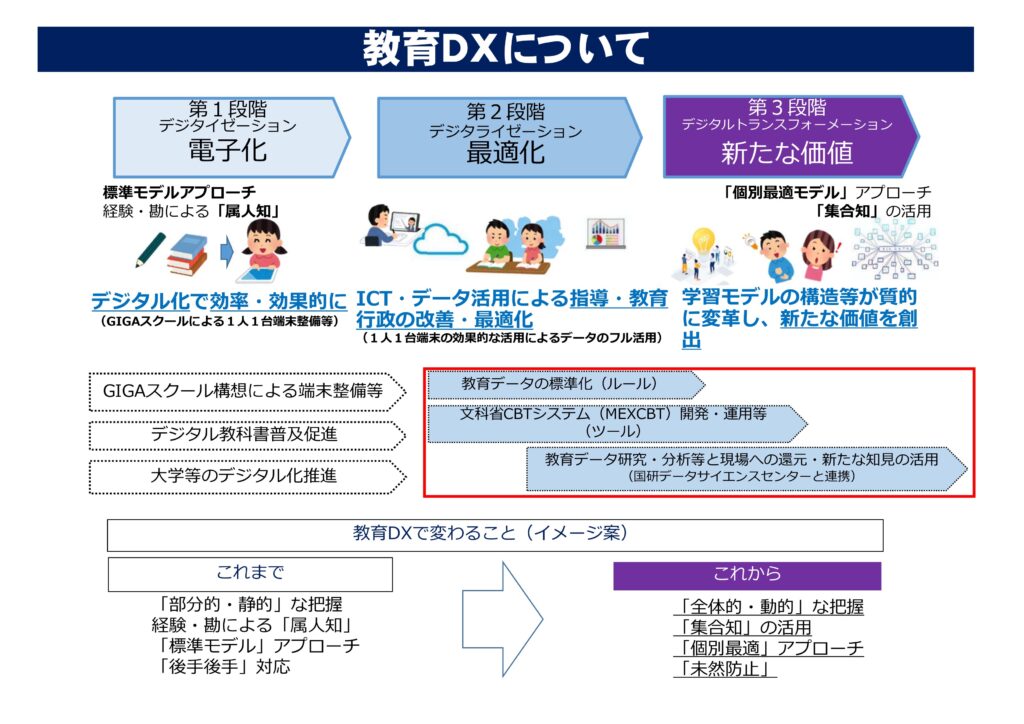
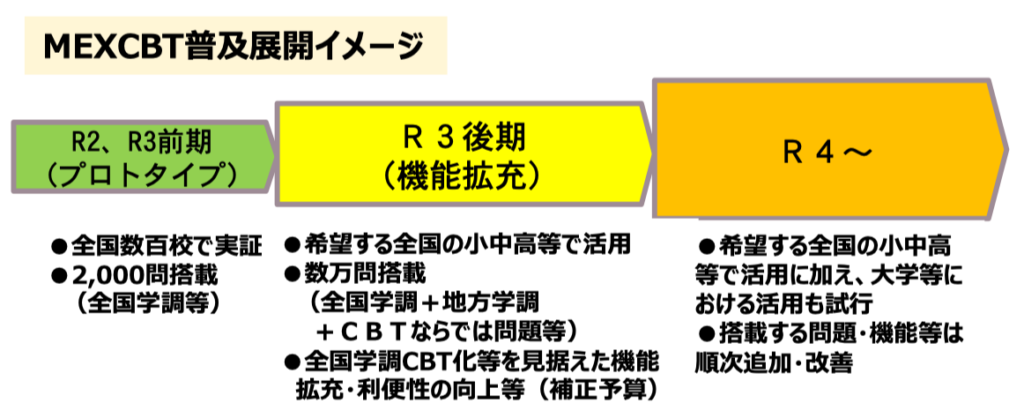
さて,教育データ標準のお話。この取り組みはいま3年目を迎えています。

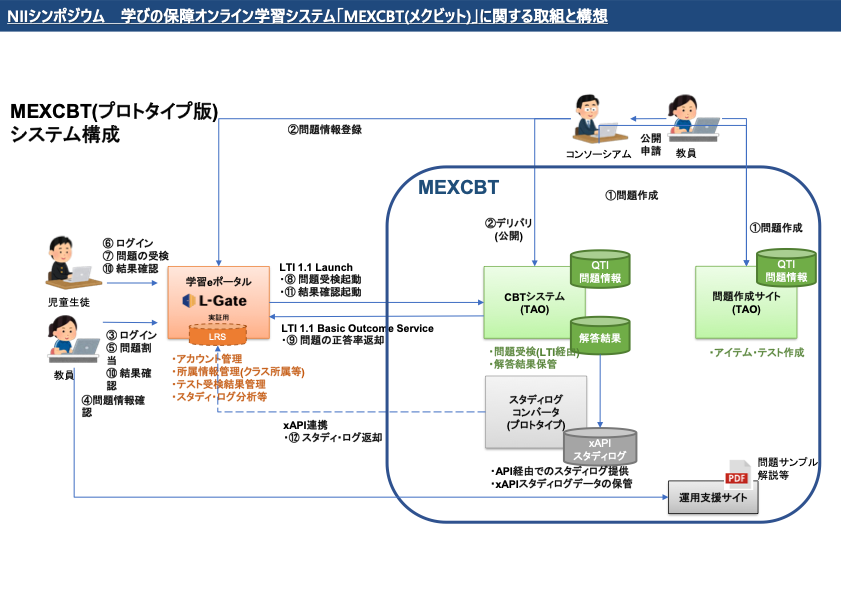
これまで「学習指導要領コード」と「学校コード」を公表し,さらに児童生徒と教職員と学校と教育委員会という「主体情報」に関するデータ項目の定義を公表しました。下のリンクが文部科学省「教育データ標準」のWebサイトになります。

前回も見ましたが再度,そこで公開されている「主体情報」のデータ項目の一覧を覗いてみましょう。
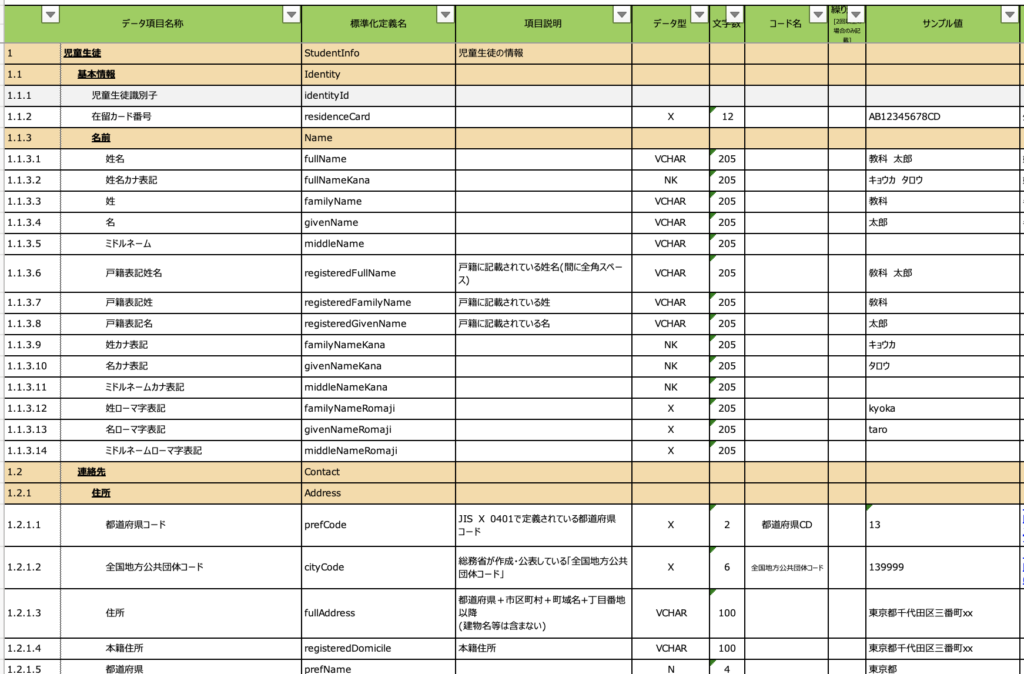
図の文字が小さくて読めないとは思いますが,児童生徒の主体情報についてずら〜っと項目が羅列されていることが分かります。
「こんなにたくさんのデータ項目をつくって個人の情報を記録するのか!!」と抵抗感を抱きたくなりますが,こういうものはあらかじめ用意しておくことに意味があります。
つまり,データをしまう場所は確保しておくけど,実際にデータをしまうかどうかは別の話。
たとえば「ミドルネーム」という項目は,日本ではミドルネームもっている人がまだ少ないので,実際には使わない空っぽな項目になりがちです。だからといって,この項目定義をけずってしまったら,ミドルネームを持っている人達が自分の名前を記録できなくなってしまいます。
文部科学省の説明では…
(留意点) ・標準化の対象はデータの全てを教育データ項目を網羅しているものではなく、データの相互運用性を図る観点から全国的な定義の統一が必要なものを中心に優先的に整備している。 ・ここで定義している情報を各学校等で集めなければならないものではない。(法令等で規定されている情報等は当該規定に従う必要がある。) ・標準項目以外に各学校設置者、学校で必要と考えるデータがあれば独自に定義して活用することは可能。
という留意点が付されています。「これが全部じゃないよ」「全部集めるわけじゃないよ」「新たに項目作っていいよ」というわけです。
児童生徒の名前は「fullName」という定義名にして,一方,教職員の名前は「staffFullName」という定義名にすれば区別がつくでしょ…といった約束事が項目ごとにずら〜っと決められている。そのことがとても大事だということです。
—
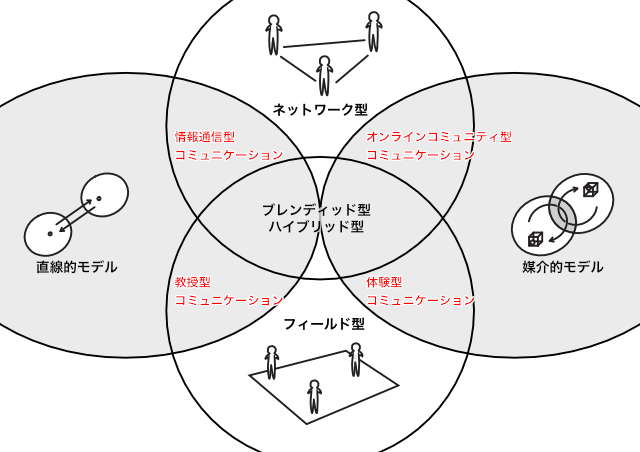
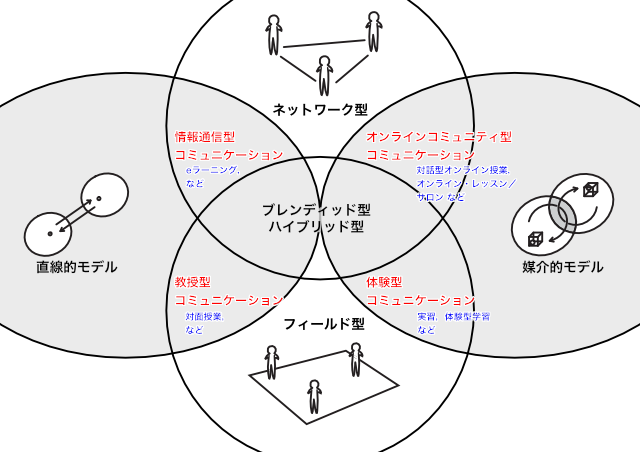
教育データ標準とは,たとえて言えば,種類の豊富なバイキングメニューです
私たちは食べたいだけのメニューをバイキングから選んでトレイ皿の上に盛りつけていくことになりますが,とはいえ栄養バランスにも気をつけたいので定番メニューは押さえつつ選ぶといった調子になるわけです。
教育データの場合,好き勝手な組合せでは具合が悪いこともあります。そこで,おすすめの組合せ「推奨データセット」なるものを用意して,どれを選んだらよいか迷う人達に提示しようというアイデアも出ています。
とはいえ,このおすすめセットの選定は,言うほど簡単ではありません。
「主体情報」(個人情報)といった,特定対象物を表現するためのデータセットを決めることは,ある程度分かりやすい作業です。
しかし,教育データは「主体情報」×「活動情報」×「内容情報」という異なる区分を掛け合わせることが前提となります。これは「個人データ」+「成績データ」といったシンプルな話に留まり得ないということです。
いや,どうも周りの皆さんは,そのシンプルな話にしたがっているようです。
〈教育データセット〉=「個人データ」+「成績データ」という構成で利用されると想定できれば,〈教育データセット〉−「個人データ」によって匿名化された成績データの集合をビッグデータ分析が可能であるともっていけるからです。
これを〈教育データセット〉=「個人データ」+「活動データ」+「成績データ」としても同じような論法で分析の対象に出来るということかも知れません。
確かに,現実的にはそういう教育データの推奨セットを提示することになるのかも知れない。
けれども,それは前回の駄文で書いたように,管理者や開発者には意味があるとしても,利用者にとっての教育データセットとしての意味は生み出せるんだろうか?と疑問符が浮かぶわけです。
—
もう一度,教育データ標準が描いている情報の区分を見てみましょう。
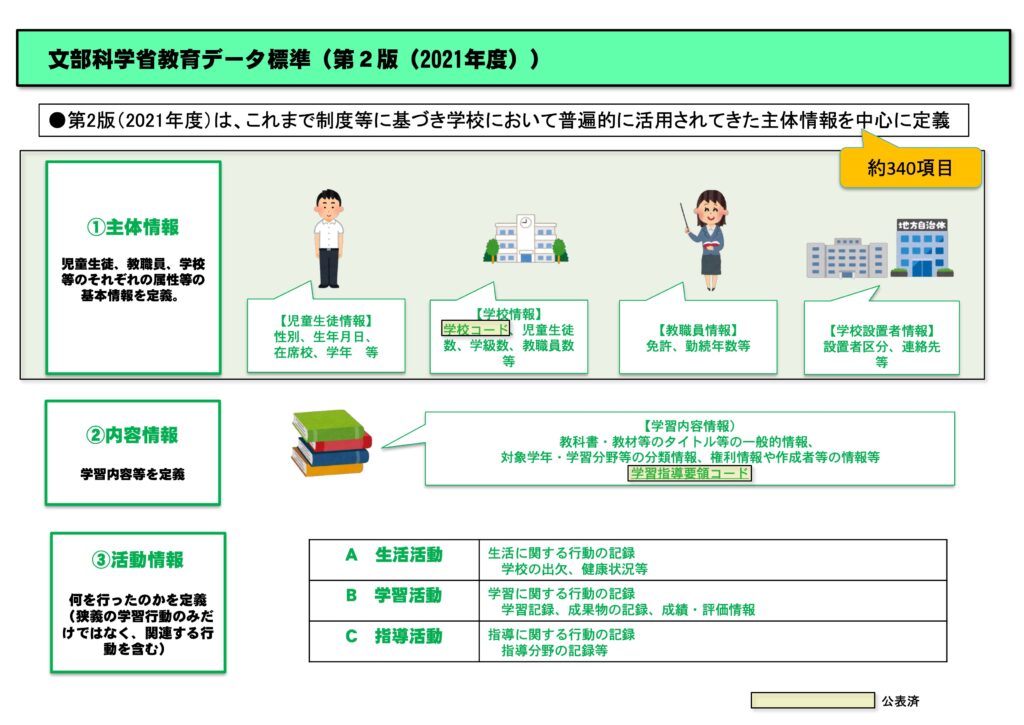
教育データ標準というバイキングメニューから,データセットを盛りつけるだけの準備は整っていません。用意できたメニューは〈主体情報〉のデータ項目と学校コード,〈内容情報〉の学習指導要領コードだけです。
大きな区分の残りひとつ〈活動情報〉を記録するためのデータ項目も早く定義しなければなりません。

文部科学省としては〈活動情報〉を児童生徒の「生活活動」と「学習活動」,教職員の「指導活動」に区分して検討することを考えているようです。これはこれで検討をしてもよいでしょう。
けれども,いよいよ〈主体情報〉×〈内容情報〉×〈活動情報〉のデータセットを考えるとなると,実はこれらを盛りつけるための「トレイ皿」に注目しなければなりません。
仮に呼ぶなら「教育データコンテナ」という捉え方で教育データを組み合わせる必要があります。
コンテナといっても,別にそれほど大そうなものではありません。
たとえば校務や学習系アプリケーションで利用されている名簿交換の技術標準であるOneRoster(ワンロースター)では,複数のCSVファイルを束ねる形も採用していて,「manifest.csv」というコントロールファイルで複数のCSVファイルの管理情報を記録するように定めています。これも言ってみればコンテナのようなものです。
〈主体情報〉〈内容情報〉〈活動情報〉を束ねるコントロール情報を含んだ「教育データコンテナ」として扱うようにすれば,今後新たな情報区分が増えたとしても教育データコンテナに加えるだけで対応ができます。
—
〈主体情報〉〈内容情報〉〈活動情報〉を「〈主体情報〉+〈内容情報〉+〈活動情報〉」して,これを教育データコンテナとして扱うことも可能ですが,繰り返すように「〈主体情報〉×〈内容情報〉×〈活動情報〉」する形で扱うことを考えたいのです。
さっきから,足し算と掛け算で何が表わしたいのか,読者には意味不明かも知れません。
端的には,教育データコンテナ自体にデータ本体を保持するかしないかの違い,といってもよいかも知れません。
たとえば,教育データコンテナに〈主体情報〉そのものは保持されない,あるいは識別子のみ保持されるといった構成です。識別子がある場合も,識別子からAPI等で主体情報にさかのぼれる場合と,主体から一方方向に認証できるだけの場合が考えられます。設定次第で教育データコンテナを分析研究用のビッグデータセットとして直接利用できるかも知れません。
個人的に,教育データコンテナは〈活動情報〉を土台としたものになると考えていて,そこに〈内容情報〉が内包される形をとるのが自然ではないかと考えています。活動を単位とした教育データコンテナが無数に生成されるというイメージです。そして,無数にある教育データコンテナの中から関係するものが〈主体情報〉によって領有されるというわけです。(逆に言えば,手放すこともできる理屈です。)
そうなると,当然のことながら教育データコンテナを格納していく場所が必要になることが見えてきます。
この場合の「格納」は技術的にデータを記録保持する場所という意味もあり得ますが,もう少し抽象的なデザインレベルの議論を続けさせてもらうと,私たちが教育データコンテナ(活動単位)を把握するための枠組みが必要だということです。
それは,もうシンプルに「タイムライン」を考えればよいのではないかと考えています。
この部分は,教育データコンテナを格納するアイデア次第で,いろんな広がりが生まれる部分と考えていて,うまくいけば学習eポートフォリオに再び光が当たるかも知れない領域ですが,技術的な設計をちゃんと組み立てて,それを一般の皆さんにも理解してもらわないと,また個人データが私企業に流れるとかなんとかで誤解を受けてしまいかねないところだと思います。
ただ,少なくとも「学校タイムライン」は教育データ標準の範疇で扱えるのではないかなと考えています。
—
ここで視点を変えて,学校の教育活動をデータとして整えていくことを考えてみたいのです。
今後,学習者一人ひとりの学習活動のパスウェイ(道筋)はますます多様化していきます。それを学習者タイムラインとして記録していくというアプローチも当然あってよく,自分の学習履歴が教育データコンテナの集積として時系列的に記録されるというのはイメージしやすいと思います。
もう一方で,学校という場はどうなっていくのか。
時間割どおりの授業が展開する昔ながらの風景が続くところもあるでしょうし,チャイムもなく学習活動は個人個人のプランにもとづいて展開していくといった学校も当たり前のように存在するかも知れません。あるいは,もう実空間に集まるといった形ではない遠隔や仮想空間上のコミュニケーションとして学校という場が存在することもあるかも知れない。
いかなる形の学習活動(それを記録する教育データコンテナ)が生成されるとしても,それを学校という場の活動として取り込み位置づけることが必要です。まぁ,そんなに多様な現実になったら,そこまで「学校」という枠組みに固執しなくてよいんじゃないかとは思いますけれど,とにかく学校が存在するというならば,学校として教育データコンテナを格納できるような土台を用意しておきたいわけです。そんな土台が必要ないというならば,逆説的にもはや学校という場もいらないということです。
学校タイムラインは,素朴に表現すれば一番最初に言及した「時間割」をベースにしたものです。
昭和な学校を想定して説明するなら,何年何月何日の月曜日1時間目といった「活動時間枠」毎にどんな集団がどんな活動を行なったのか,時間割の情報をもとに学校タイムラインの土台を整えておくのです。
この学校タイムラインの土台が整うだけで何が可能になるかというと,「このクラスの先週火曜日の3時間目は何の授業だった?」という検索に対して答えられるようになるということです。
たとえば,AlexaとかGoogleアシスタントとかSiriと接続してみたとしましょう。
社会科の先生が,昨日の2時間目に社会科授業をしていて,今日は3時間目に社会科授業の続きをする状況を想像します。いざ授業を始めるときに先生はパソコンにこう呼びかけるのです。
「OK,昨日のスライド表示して」
するとAIアシスタントは,学校タイムラインの情報をもとに,現在が社会科授業であることを察知し,次に昨日の授業から社会科が実施された時間帯を検索し,その時間帯に開かれたスライドファイルをパソコンから呼び出してスクリーンに投影する…なんてことが可能になります。
これは学校タイムラインの情報だけを利用した想像事例ですが,このように学校のカリキュラムを時間割ベースでデータ化した学校タイムラインを土台に,学習集団の名簿データや教育データコンテナとのリレーション(関連)を結んでいくことによって,学習者の学習活動を学校タイムラインに配していくことが可能になります。
もちろん,教育データコンテナを児童生徒の主体情報とセットで学校タイムラインに結びつけていくためには,初めの段階で学習者から学校関係者に対して情報アクセスに関する包括的な許諾を手続きする必要があると思われます。こうした学習者の領有する教育データに対する学校関係者のアクセス権は,在学期間中に限定するなどの時限式であったりもするかも知れません。
いずれにしても,学習者は自身の学習者タイムラインの上に教育データコンテナをプロットすることによって学習履歴をコントロールできるし,学校関係者も許諾にもとづき学校タイムラインのもとで教育データコンテナへのアクセスが可能になるというデザインです。
これとは別に学習eポートフォリオのような形で教育データコンテナをプロットできる仕組みが出来れば,それを転校する際の教育データの受け渡しフォーマットとして利用することができるかも知れません。それはそれで交換用のフォーマットを考える必要があると思いますが…。
—
今回は,図の作成まで手が回っていないので,まさに駄文の羅列でアイデアを書き連ねることとなり,伝わるものも伝わらない感じになっているかも知れません。
途中,考えるために作図はしていましたが,ラフなもので,完成もしていません。
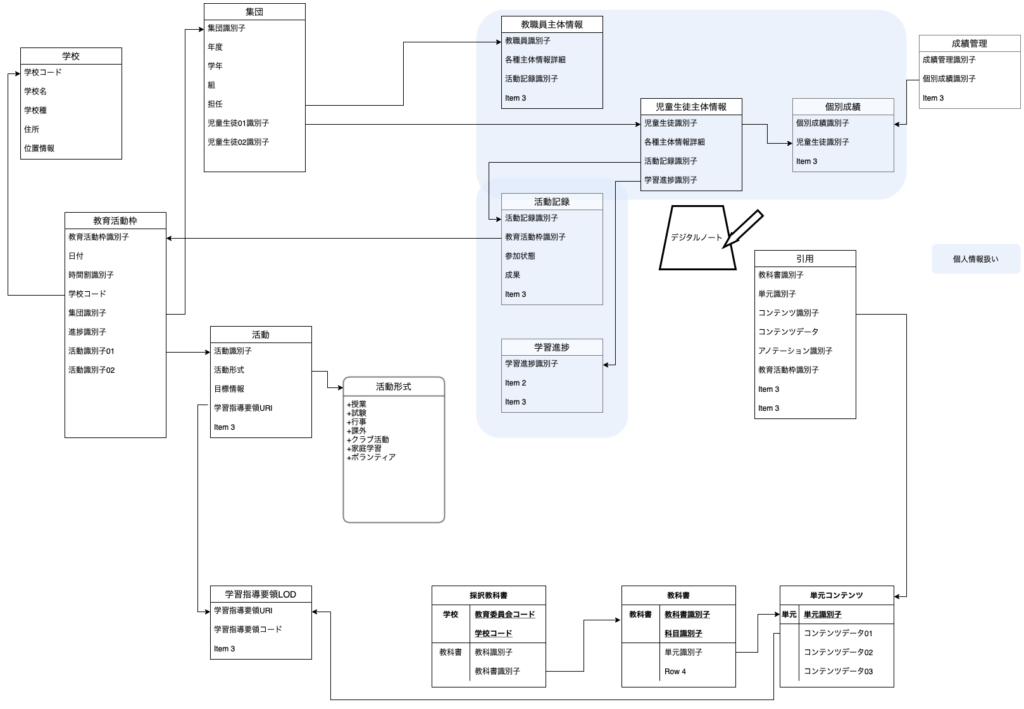
実際の「教育データ標準」的には,活動情報についてはオンラインコースの学習履歴を記録する技術標準を土台に考えたがっているようで,果たして私たちの実際の学校の教育活動にどれだけフィットするものになるかは,正直よく分かりません。
途中にも書いたように,単なる学習成果のみならず,学習活動の道筋(パスウェイ)も重視されるようになるとすれば,単なる学習コースの履歴だけでなく,異なる学習活動が組み合わさった道筋自体を表現できるデータ構造が必要になってくるはずです。
今回の妄想は,そのパスウェイをタイムラインとして表現したわけですが,あるいはそれはマップという表現形式かも知れませんし,それはいろいろあり得ると思われます。
そのいろいろ様々あり得るということを考えると,私たちは教育データ標準を決めるというだけでなく,教育データ標準を定期的あるいは継続的にアップデートするプロセスなり体制なりを確立することの方が重要なのではないかとも思えます。
物事は生み出している間は活発にやれていても,ピークに達すると衰退していくのが常。
そのことが分かっているなら,むしろその対処を真剣に考えることの方が重要に思えます。