なんとなく教育データ標準のことをぼんやり考える日々の記録です。(#教育データ )
教育データ標準の世界は,長らく続く国際標準規格の積み重ねがありますから,素人考えで語るのはやめて,そろそろあなたも標準規格ベースでしゃべりなさいよと,虎ノ門あたりに集っている人達からお叱りが飛んできそうです。
—
これまで「主体情報」「内容情報」についていくらか成果が公表され,今年度は「活動情報」について何かしらかたちを示しなさいというのが文部科学省の宿題。
私は駄文で「教育データコンテナ」といった呼び方で各種の情報を盛りつけるお皿を考える必要があるとお説ぶっていたわけですが,それにあたる標準規格はすでに存在しているわけです。
「Experience API 」と呼ばれる学習経験の記録と共有のための規格です。
経験(experience)のためのインターフェイス規格という正式名称は「名は体を表わす」になっていて分かりやすいのですが,一方,略称表記は「xAPI」とされているため,こちらは補足説明されなければ何の規格だか推測が難しいです。私も長いこと「x」が何なのか知らないままでした。
Experience API(xAPI)は,「誰が/何を/どうした」という要素情報の組合せ(ステートメントと呼びます)をJSONというWebの世界でもお馴染みのデータ形式でひたすら記録していく枠組みを定めた汎用的な規格です。
要するに,活動情報の記録は「xAPI」を使いなさいということです。
確かに教育データ標準が始まった当初から,そういうつもりであったことは明記されています。
「③活動情報」の国際標準規格に…
ちにみに「xAPI」とともに「IMS Caliper Analytics 」という規格名も併記されていますが,こちらも学習履歴を記録・共有するために作成された規格の一つであり,両者は重複部分を持っているとされています。
どちらがよいのかは議論が残るところですが,個人的にはxAPIの方がオープンでよいかなと考えています。一方のCaliper Analyticsは規格管理団体のIMSが他の規格とともに推していることもあるので,兼ね合いを考える人々はCaliper推しかも知れません。両者歩み寄りの動きもあるとかないとかで,しばらくは併存すると思われます。
それで,日本はどうするのか?ですが,これはわりと明解で,デジタル庁で閲覧できる「教育データ利活用ロードマップ (令和4年1月7日デジタル庁、総務省、文部科学省、経済産業省)」にはっきりと記されています。
教育データ利活用ロードマップ(19頁)
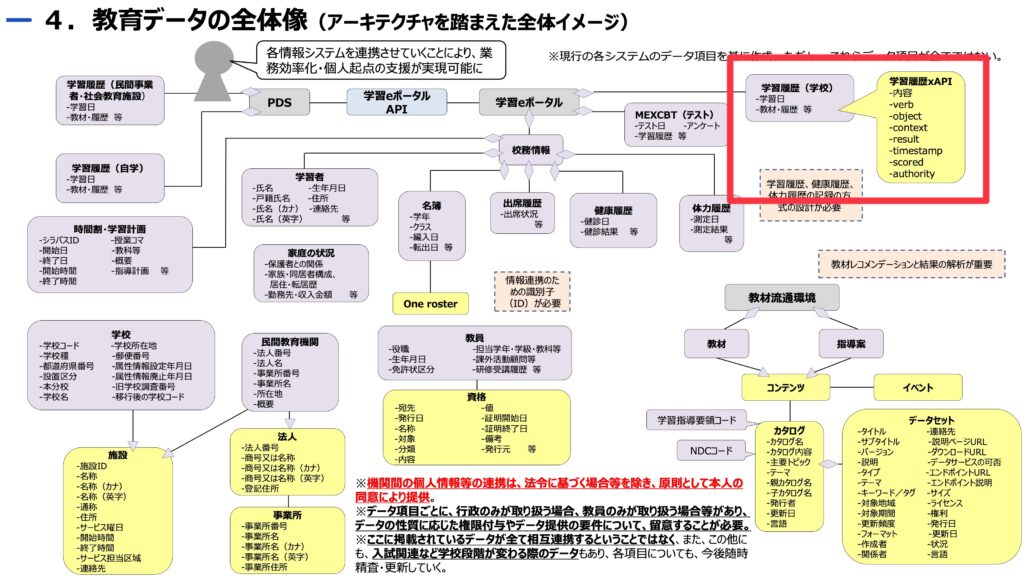
「学習履歴 xAPI」とご指名
スライドの反対側にはまた別の「学習履歴」の情報も視野に入れられているので,IMS Caliper Analyticsやら何やらの規格はそちらで活躍することも想定されているのだと思います。
—
さて,こうやって「初めからそうだった」と書いている私にしてみても,あれこれ掘り起こしてみたら「そうだったんだ…」という感じで見返しているところ。
確かに書いてはあるし,初めから関わっている人達には自明な話だったんでしょうけれど,活動情報の教育データ標準作業が,xAPI規格を扱えるようにしたい話なんだよとは,誰もはっきり教えてくれたり解説してくれたことはなかったように思います。
最近「教育データ利活用に関する有識者会議」で文部科学省 教育DX推進室・桐生室長の発言によって,素人の私にもこの辺がようやく明確になりました。
教育データ利活用に関する有識者会議(第13回) 47'25''あたりから
https://youtu.be/Mstu2V2sFMM?t=2845
桐生室長「教育データ標準の方の話がありましたので,ちょっと現状をお話したいと思います。教育データ標準第3版を今年中に出すという話が進められております。中でも活動情報をきちんと検討して,その枠組みと具体的な姿というものをお示しできるよう,いま文科省の委託事業の中で検討を始めております。この中で学習ログも,eポータルからxAPIで 書き出す際にどういった考え方で,どういう風にやっていくのか,といったような議論を今進めております。 これまた近々,こちらの会議でも諮らせていただいてご議論進めさせていただければと思います。」
教育データ利活用に関する有識者会議(第13回)より[読みやすく文末改変] というわけで,学習eポータルやMEXCBTなどのシステムで,学習履歴や学習経験を記録するためにxAPIを使えるようにして欲しいというのが現在目指していること。
そして,その作業を,委託事業の作業チームの皆さんが頑張ってるっぽいです。
けれども,xAPIを使えるようにするっていうのは,学習eポータルを開発している各社の開発者が頑張る話じゃないのでしょうか?なぜ,文部科学省から委託されている事業で取り組んでいるのか?
標準規格があるなら,そのルールに合わせればよいだけの話で,何故あらためて検討する必要性があるのでしょうか?
もしもあなたが,そんな疑問に気がついたとしたら,いよいよ国際標準規格の沼の世界へと誘われる準備が出来たということかも知れません。
—
データ交換に支障が出ないように共通ルールを定めることが標準規格の目的です。
共通ルールと一口に言っても,何を共通化するのかは様々です。データの形式,通信の手順,項目の定義など概念的な構造から技術的な規則まで目的に応じて非常に多様です。
だから,標準規格というのは,かなり時間をかけて育てていくように構築されます。
多様なものに対応するためには,共通の土台となる大枠の規格を構築しておいて,目的や領域に応じた個別具体的なルールをその土台の上に組み上げていくといった形をとることもあります。
xAPIは「あらゆる学習履歴を記録する」というかなり大きな目標を掲げた規格で,個別具体的な履歴情報の詳細な記録方法については「プロファイル」という別ルールをみんなで決めるという仕組みを採用しています。
先ほどデジタル庁のスライドで見た吹き出しをもう一度見てください。
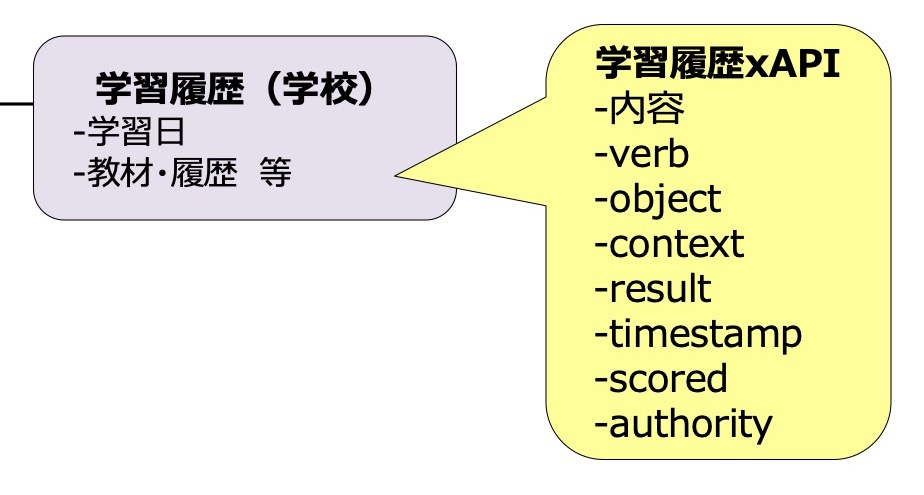
「内容」「verb」「object」「context」「result」「timestamp」「scored」「authority」という単語が並んでいるわけですが,これらはxAPIの記録(ステートメント)に含める項目です。
そして,実際に含める項目は,必須項目を除いて,実は増えたり減ったり,項目の構成は自由になっています。xAPI自体は,項目をいろいろ含んで記録できるよぉ,それを規格に従うことで柔軟に交換・共有できるよぉ,という大枠だけ規格化しているのです。
しかし,項目を自由にできると,そもそも交換するときに困るって話じゃなかったっけ?
という指摘が出るのは当然のこと。もちろん,自由にできるからといって,自由にやってよいとはされてないわけです。
上図の黄色い吹き出し「学習履歴xAPI」は,紫色の角丸四角「学習履歴(学校)」から出ていることはお分かりいただけると思いますが,実は,この「学習履歴(学校)」というものを記録するために「学習履歴xAPI」の吹き出しの中の項目は,本当に「内容」「verb」「object」「context」「result」「timestamp」「scored」「authority」でよいのか?は,まだ答えが出ていないのです。
デジタル庁も文部科学省も,まだ「学習履歴(学校)」に相応しい「学習履歴xAPI」の中身が何なのかを決めておらず,その項目構成を委託事業の作業チームに整理して欲しいと考えているわけです。
たぶんですが。
—
どうも話がまるで見えない…という方もいると思います。
そもそも「学習履歴(学校)」って何なのよ,という素朴な疑問は残っているでしょう。
子どもたちの学校での学習活動を記録する場合に,何でもかんでも記録するのか?それって監視環境じゃないか?という疑問や不安もおのずと出てくると思います。この話は,どうしても実際の運用範囲の問題に関心が向かってしまいがちです。
疑問に対しては,先の文部科学省の室長発言にもあったように,現時点で想定しているのは「学習eポータル」で扱う学習活動が記録の対象だといえます。つまり学習に利用したWebサービスの利用記録や成績情報といったものです。
xAPI規格誕生の経緯的にも,そうした運用が真っ先に想定されています。
そもそもxAPI規格は,それまでeラーニングの世界で拡張され続けてきたSCORM規格を置き換えるものとして登場しました。そんなこともあってか,xAPI規格はWebベースドな学習活動を記録する用途に用いられることが多いのです。
xAPI規格に組み合わせる個別具体的な目的のためのルールとして「cmi5 」というプロファイルがあります。このcmi5というのがeラーニングシステム(Webサービス)における学習記録管理を目的とした詳細なルールを規定して,xAPI規格を補っているというわけです。
文部科学省が今回の教育データ標準の作業の目標として考えているのは,学習eポータルにおけるxAPI規格の詳細なルールの規定をどうするかであることは,ご理解いただけると思います。そして,少し目的が違っていることもあって「cmi5」ではなさそうだ,ということも何となく分かっています。
—
xAPI規格を作成したのは,米国国防総省のAdvanced Distributed Learning (ADL)という団体です。しかし,組み合わせるプロファイルは必ずしもADLがすべてつくるわけではありません。
加えて,xAPI規格は,国際的な技術標準化機関であるIEEE のもとで新たなバージョンや,様々なプロファイルが取り組まれ ており,国際標準規格としてもステップアップしているようです。
また,日本学術会議の提言「教育のデジタル化を踏まえた学習データの利活用に関する提言 −エビデンスに基づく教育に向けて− 」にも記載されている米国のCommon Education Data Standard (CEDS)の取り組みは,項目定義の規定はもちろんのこと,各州で異なる項目定義を調整するツールを提供して,できるだけスムーズなデータ交換に役立てられるような取り組みを続けています。
こうした先行する取り組みやプロファイルを参考に,日本の学習eポータルで利用できるxAPI規格の独自プロファイルの作成が進められている…んじゃないかと,何となく思ったりしている今日この頃です。