AIチャットは学習利用にも可能性
昨年11月末にChatGPTが公開され、深層学習技術が牽引する人工知能(AI)フィーバーが続いています。
そして先日はChatGPTがベースとしている言語モデルのバージョンアップ版GPT-4がリリースされ、より尤もらしい返答をするようになったことが話題です。

このタイミングで、GPT-4搭載のサービスも発表され、教育分野ではカーン・アカデミーがチューター・チャットボットKhanmigo(カーミーゴ)を試験中であることが公表されました。
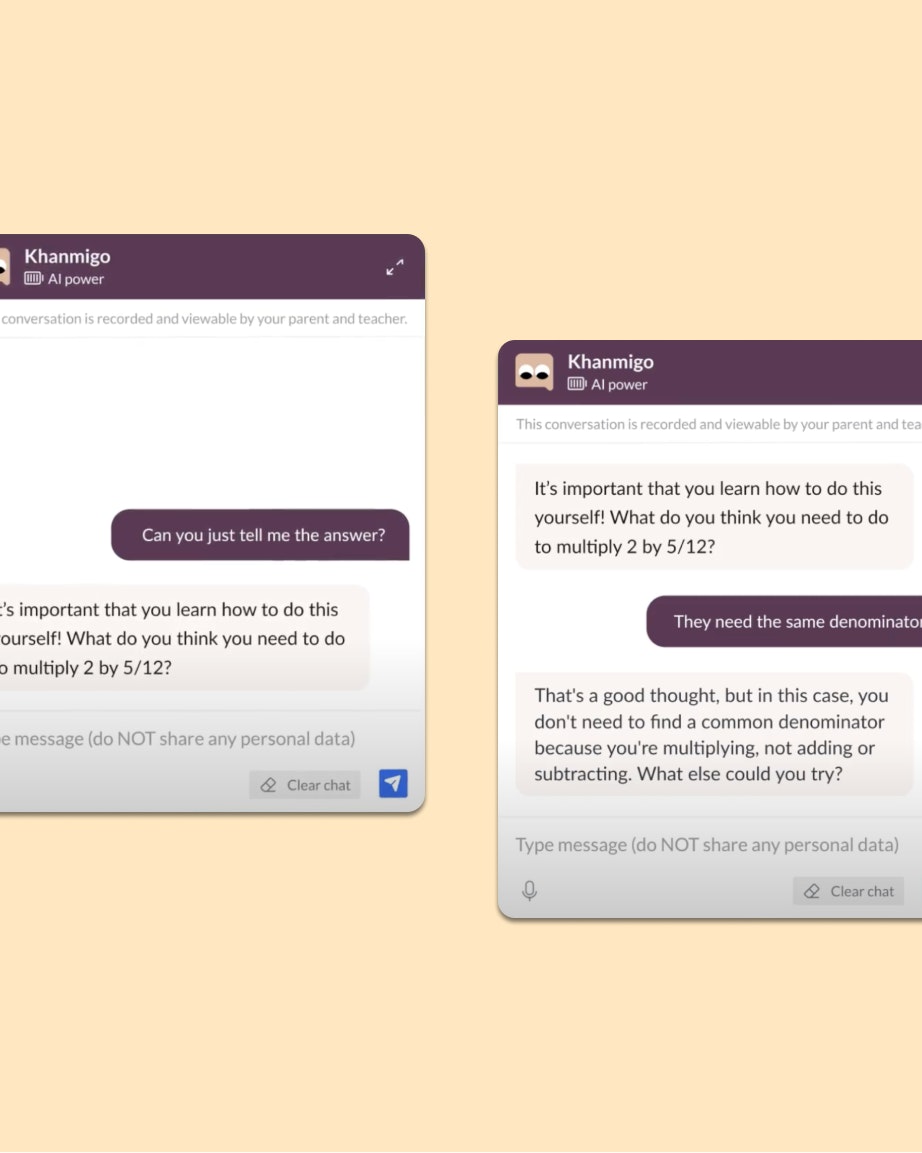
大規模言語モデルをベースとしたAIチャット技術を教育分野に導入する具体的な一つの姿を見せてくれます。
個々人に向けて最適化された学習支援にAIを用いる場面が、単に最適な教材や問題の提示といった場面だけでなく、教材内容に関する質疑応答や問題に取り組む過程のアシストにも広がっていく可能性が示唆されているというわけです。
確かにGPT-4はかなり賢く返答しているように見えます。
言語モデルとは言葉のガチャ
言語モデルをどのように例えるとその特性を説明しやすいだろうかと、ぼんやり考えています。
言語モデルから生成される言葉や文章の危うさを印象づけるために…
ChatGPTのベースとなっているGPTという大規模言語モデル(LLM)は、世に出回る大量のテキストデータを学習データとして作られた言葉の「ガチャ」である。
と例えてみてはどうだろうと考えています。
希望するものが出てくるとは限らないという点がガチャに似ていて、何が飛び出す変わらないという不確定性を含められると思ったからです。
ただ、言語モデルをガチャに例えるのは、すぐに苦しくなります。
たとえば、ガチャの場合、トイ(おもちゃ)がカプセルに閉じこめられて用意されているので、取り出されるトイそのものは保証されたものなのに対して、言語モデルの場合、言葉が「トークン」という単位に分解されて存在するため、拾い出したトークンから組み立てられた言葉の内容までは保証されてないという違い。
推論によって言葉の表現が正しく組み立てられていても、内容までは保証されていないのだということを理解してもらいたいのにガチャの例えではその部分はうまく対比的に説明できません。
そもそも言語モデルはトークンを膨大な次元の数値にもとづいて配置(埋め込み)して、その配置の距離的関係を意味の関係性として処理することができるという前提もガチャではまったく表わせていません。
というわけで「言語モデルは言葉のガチャである」というのは、かなり大ざっぱな例えでしかないと言わざるを得ません。
より特定のタスク(プログラムコードを生成する)においては、かなり確実な結果を返してくる場面もあるため、その点でもますます例えとして難しくなります。
—
AIはタスクに応じて様々な手法やモデルが存在しますし、私たちが利用できているサービスなどは素の言語モデルを晒して使っているわけではなく、いろんなチューニングや評価機構、補完機能を組み合わせて構成されたものです。単純な例えで全てが賄えるわけもありません。
賢く見えるし、正しい情報を提供しているようにも見えるし、正しい情報であることもほとんどだろうけれども、それでも、それは「ガチャ」くらいの程度のものだというまなざしから始めた方が、いろいろと誤解しなくて済むのではないかと思います。