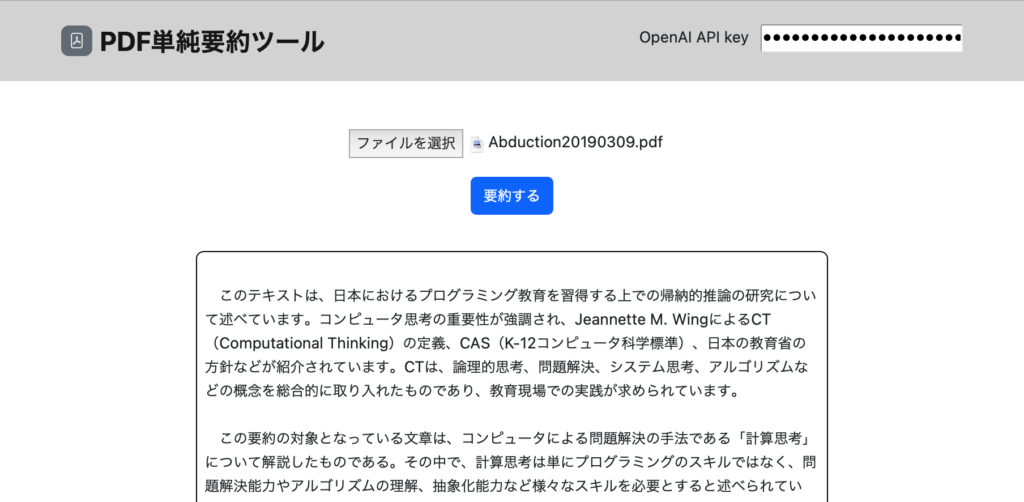
現在、サム・アルトマン(Samuel H. Altman)氏がCEOを務めるOpenAIが世界を揺さぶっています。
深層学習によって進化したAI技術は、インターネットのように基盤技術として様々な社会経済機能の中に取り込まれようとしていて、つい最近のChatGPTの登場によって一般人にも分かりやすい形で認識が広まったということになります。
サム・アルトマン氏は精力的にメディア対応をしていて、人々の疑問や懸念などにちゃんと考えを返している点で、革新的なものに対して起きがちなヒステリックを和らげているようにも思えます。
残念ながらテレビ東京の特集番組は見られていませんが、YouTubeに公開されている一部分を観ると日本語を始めとした多国語についても前向きのようです。
—
先日、文部科学省で「今後の教育課程、学習指導及び学習評価等の在り方に関する有識者検討会」第3回が開催されていました。
学校で使う教科書が準拠する「学習指導要領」(教育課程)を改訂する作業を開始するための準備検討会です。つまり、学校教育の方向性を決定する会議となり、大変重要な助走です。

この会議で安宅和人先生がゲストスピーカーとして発表されたのですが、会議の傍聴募集段階では確定していなかったためか、そのことは何も告知されていませんでした。

そもそも文部科学省の会議に関心を示す人達は少ないですが、安宅先生の活動に関心のある人は多いはずですので、事前にわかっていれば、通常よりも傍聴者は多かっただろうと思います。
先に書いたように、この会議は新しい学習指導要領を改訂する作業に先立つ助走的会議です。実際の改訂作業は大臣からの諮問によって中央教育審議会が請け負い、下部部会が審議したあと、答申が出来上がった頃に世間で話題になって「あーでもない、こーでもない」と騒がれます。
しかし、この助走的会議で議論されている内容が、そもそもの「諮問」を方向づけるものになるため、世間の人々が目を向けるべきは、この「今後の教育課程、学習指導及び学習評価等の在り方に関する有識者検討会」であるべきなのです。
そのような場に、安宅先生が招かれて意見を発表されたのですから、安宅先生が日頃から各所やメディアで語られている内容に関心を寄せている人々の関心を、この会議にも寄せてもらう絶好の機会なわけです。少なくとも安宅先生のご主張を学校教育の議論の中に直接投げ込む機会を多くの人々が目撃することは、いろんな意味で重要だと思われます。

会議の様子は教育分野の専門新聞である「教育新聞」が即日記事にしました。(ちなみに教育分野の専門紙は、意外かも知れませんが何紙もあって、他にも教育家庭新聞、日本教育新聞、内外教育などあります。)
教育新聞は、大変マイルドというか、オブラート力が発揮された執筆手法をとるメディアなので、この記事も会議のおおよそを捉えてはいるのですが、実際に傍聴した場合の印象とは違うところも多いです。むしろ、傍聴していたときのスリリングさはまったく省かれています。どうぞメディアリテラシーを発揮してお読みいただければと思います。
また、実際に傍聴した場合にも、どうか検討会委員や文部科学省事務の人々あるいはゲストスピーカーのやりとりについて短絡的に責めないでいただきたいと思います。
もしも抵抗勢力のようなものがあるとすれば、今回の検討会議にはそういう存在はありません。むしろ学習指導要領改訂作業が始まってから、各教科に関する実際的議論が始まったときに、得体のしれない抵抗勢力のようなものが生まれ、世間の人々が知らず関心を寄せない中で、その得体のしれない抵抗に前向きな人々が消耗戦を強いられるということが、ずっと続いてきたのです。
この「今後の教育課程、学習指導及び学習評価等の在り方に関する有識者検討会」は、助走的な会議であれど、最初の前提を決める場であるからこそ、そのような自然発生する抵抗勢力を抑え込むための強力な根拠なり武器を得ておかなければならない役目を負っています。
今回、安宅先生が出席されたことで、本来議論を闘わせるべき文脈が見えていたけれど、会議時間や進行関係を考慮した大人の対応でガチで向かい合えなかったこと、そのことが全員にとって不幸だったと思います。
どうか関心のあるネットメディアが、安宅先生や委員の先生方を別の場所に招いて、じっくりと議論をしてもらいつつ、世間の関心もこちらに向けていただけるといいなと思います。
—
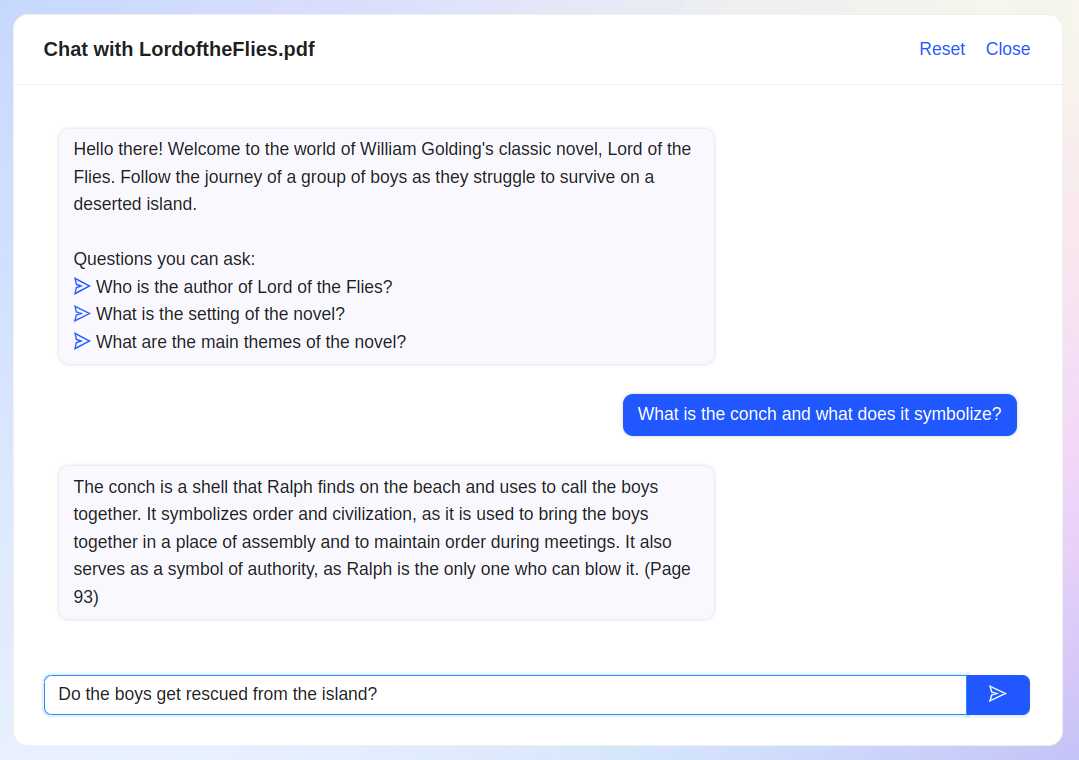
大規模言語モデルたち(LLMs)にまつわる様々な技術的進展を日々目にしつつ、安宅先生の検討会ゲスト発表を観ながら、教育との関わりでどう考えたらいいだろうかと考えたりしています。
従来までの教育は「世界に知識が偏在しているから、それらを掘り起こしに行けるよう学習すること」を目指していたと考えられます。
一方、LLMが何をしたかというと「世界の知識が言葉の関係付けで貯まっているから、そこから捻り出せるよう学習すること」を求め始めたのかなと考えられます。
それは最初に接する知識の所在が変わったというか、今まで偏在していた知識に接するためのポインタが1箇所に集約されたというか。
確かにこれまでもGoogleが世界の情報を整理しインデックス化してアクセスできるようにするという理念でやってきたことではあるのですが、Open AIが先に世間に見せたものは知識の方からやってきて私たちと同じ言葉を話せるように一所で待っている感じです。
Googleが「外に探しに行く」メタファであり、Open AIが「手元から取り出す」メタファ。
う〜ん、ちょっとこなれていませんね。もうょっと考えておきます。
たぶん、この2つは技術的には似通っているところがあって全く別物ではないのだけれど、人間の自然言語に寄り添って知識を提示できるようになったことが、これほど大きな違いを生むのだということを考えずにはいられないわけです。
そのようなときに、日本語という言語を使って教育や社会活動を行なう私たちは、英語などを流暢に使って動いている人々や世界との関わり合いの中で、どんな日本社会を思い描き、どう成長して、どう生きていくことができるのか、もっと議論しなければならないのだと思います。
「問いベースの教育」ということも大事ですし、記事ではほとんど省かれてしまった数理・データサイエンス・AIといった領域、あるいはコンピュータに関わる教育をもっとメインに置くことについても真剣に考えていくべきでしょう。
私も学習指導要領議論は慎重さが大事であるということは理解しています。不易流行において、何が不易で、何が流行なのかを慎重に見極めることは簡単ではないからです。
ただ一方で、もう日本には、そのような慎重さを10年単位で維持できるほどの余力がない、という現実を踏まえるとするなら、学習指導要領の各教科もドラスティックな変化をこの機に覚悟して断行しなければ、将来世代に禍根を残すのだろうなとも思います。
〈追記〉
ちょっと忘れていたのですが、今回の改訂が目指すべきものは「改訂プロセスの改訂」であることでした。
確かに取り入れるべき喫緊の題材があることは確かですが、そのことも含めて、学習指導要領の改訂を3年毎にでもできる改訂プロセスのアジャイル化が必要なのではないかと思います。
だとすれば、今回の助走的会議の役割は極めてシンプルです。「学習指導要領の改訂プロセスの迅速化と反復が可能となるプロセス改訂を諮問すること」を示唆することでしょう。
〈/追記〉