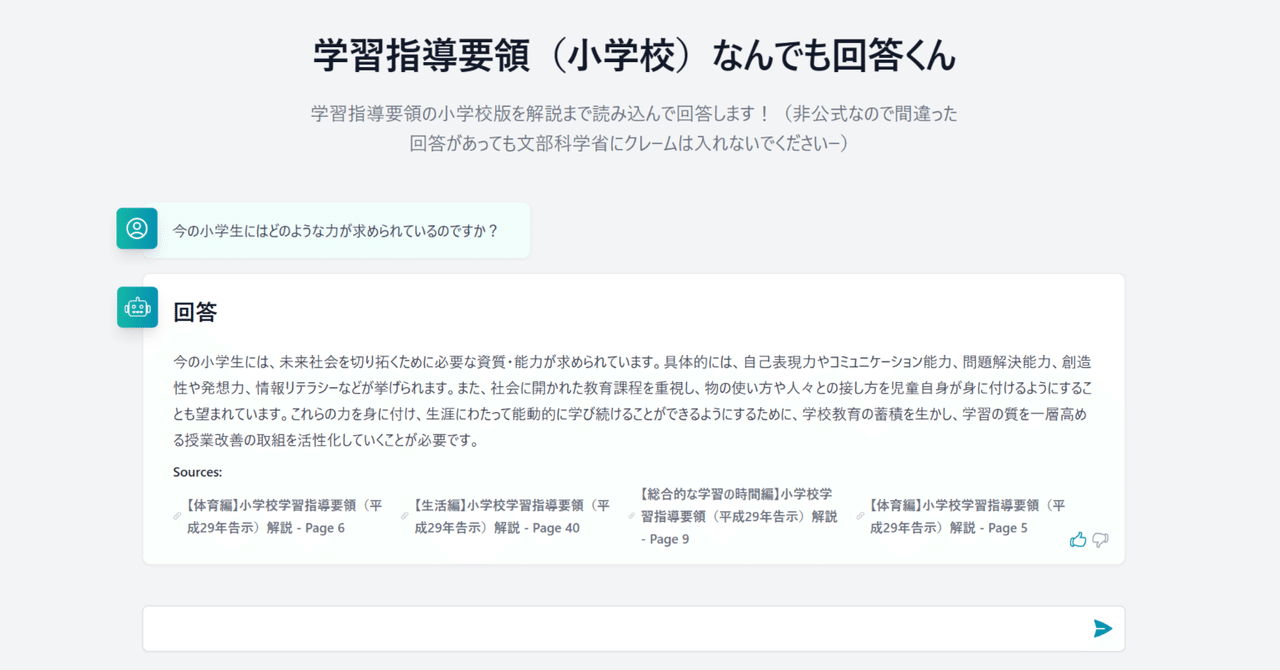
生成系AIガイドライン
シート1 大学名,学部名,タイトル,対象,author,日付,初版,URL
東京外国語大学,大学教育における AI について 東京外国語大学としての教員向けガイドライン,教員,総合戦略会議 承認,2023/3/22,http://www.tufs.ac.jp/documents/education/guideline/ai_guideline.pdf
上智大学,ChatGPT等のAIチャットボット(生成AI)への対応につい…
東京外国語大学,大学教育における AI について 東京外国語大学としての教員向けガイドライン,教員,総合戦略会議 承認,2023/3/22,http://www.tufs.ac.jp/documents/education/guideline/ai_guideline.pdf
上智大学,ChatGPT等のAIチャットボット(生成AI)への対応につい…
各大学の反応
上智大学 20230327

ChatGPT等のAIチャットボット(生成AI)への対応について|上智大学 ウェブピロティ
上智大学 ウェブピロティサイト。在学生の方に向けてさまざまな最新情報を発信します。授業の履修など各種手続きや学生生活、国際交流・留学、奨学金・学費、研究などの情報を発信します。
東北大学 20230331
ChatGPT等の生成系AI利用に関する留意事項(教員向け)
このページでは、教職員向けに、ChatGPT等の生成系AI利用に関する留意事項や関連情報を提供いたします。学生向けの留意事項はこちらです。
立命館大学 20230331
大学の英語授業に機械翻訳とChatGPTを組み合わせたサービスを試験導入 |立命館大学
立命館大学は、OpenAI 社の人工知能チャットボット「ChatGPT」と機械翻訳を組み合わせた英語学習ツール「Transable」(※1)を、生命科学部・薬学部で展開する「プロジェクト発信型英語プログラム(PEP)」(※2)の英語授業の一部において、2023 年春学期より試験導入いたします。
東京大学 20230403

生成系AI(ChatGPT, BingAI, Bard, Midjourney, Stable Diffusion等)について
目次: 何ができるか、「検索」ではなく「相談」するシステム; 仕組み上、書かれている内容の信憑性には注意が必要; 機密情報や個人情報などを安易にChatGPTに送信することは危険; 将来著作権や…
群馬大学 20230413

【在学生向け】ChatGPTなどの生成系AIについての注意喚起
Tweet 2023年4月13日 在学生の皆さんへ 理事(教育・評価)・副学長 ChatGPTなどの生成系AIについての注意喚起 ChatGPTなどの生成系AIやウィキペディア等の文章をほとんどそのまま書き写して、レポートや学位論文
島根大学 20230414

島根大学におけるChatGPT等の生成系AIの利用におけるリスク管理について ―教職員及び学生のみなさんへの注意喚起― | 国立大学法人 島根大学
島根大学は、松江キャンパスに法文、教育、人間科学、総合理工、生物資源科学の5学部、出雲キャンパスに医学部があり、皆さんの志望する学びの場を文系、理系、医系に関わらずほとんどすべての学問領域において提供している総合大学です。
大阪大学 20230417


20230418 生成AIをめぐるELSI論点をまとめたレポートを発表
大阪大学社会技術共創研究センター(ELSIセンター)のカテライ アメリア ヌル 特任助教(常勤)、岸本充生 教授/センター長、感染症総合教育研究拠点の井出和希 特任准教授(常勤)らの研究グループは、急激に世界に広まりつつある「画像生成AI」や「テキスト生成AI」などの生成AIについて、2023年3月末時点での動向分析を行い、ELSI(倫理的・法的・社会的な課題)の観点から考えられる課題をレポートにまとめました(4/12(水)公開)。
人工知能技術の進歩によって、映像や音声、画像、テキストを生成する生成AI(Generative AI)が注目されています。一方で、生成されたものの情報の偏りや誤り…
人工知能技術の進歩によって、映像や音声、画像、テキストを生成する生成AI(Generative AI)が注目されています。一方で、生成されたものの情報の偏りや誤り…
山形大学 20230418
教育における生成系AIの利用について
急速に進展と普及を見せる、人工知能(AI)を使った生成系AIに対して社会的な関心が大きくなっています。入力した質問にAIが文章を生成して答える対話型のソフト「ChatGPT」が公開されて以来、バージョンの更新とともに生成する文章の質や正確さの飛躍的な向上が話題となっています。すでに試してみたり積極的に使用したりしている方も多いことでしょう。これらを踏まえて、生成系AIの利用に関する留意事項や対応について、次のとおりお知らせします。
東京工業大学 20230420

学修における生成系人工知能の使用に関する本学の考え方について
学生の皆さんへ理事・副学長(教育担当) 井村 順一ChatGPTに代表される生成系人工知能(以下、生成系AI)が、大学におけるレポート課題などに対して使用され、世界中で大きな議論を呼んでいます。皆さんには、本学が掲げる「学生の主体的な学び=Student Centered Learning」の精神に則り、良識ある使用が求められます。本学教員とは、3月中旬に生成系AIの使用上の注意点や成績評価法につ…
岡山大学 20230421

【教職員の皆さんへ/To all faculty and staff】本学教職員の生成系AI利用に関する留意事項について/On the Use of Generative AI by University Faculty and Staff – 国立大学法人 岡山大学
岡山大学の公式サイト。
学習院大学 20230424

長崎大学20230425
東京工科大学 20230426

神戸大学 20230427
教育関係ニュース

20230217 「ChatGPT」は試験やレポートに活用すべき? 「AIがある前提で問いを立てる、出題側のセンスの課題になる」慶応大・宮田教授 | 経済・IT | ABEMA TIMES | アベマタイムズ
自然な言葉で質問に答えるAI「ChatGPT」。11月の公開から約2カ月でユーザーが1億人に達するなど注目を集める中、教育に与える影響について、11日のABEMA『NewsBAR橋下』で橋下徹とゲスト出演した宮田裕章・慶應義塾大学医学部教授が議論した。【映像】「橋…
20230325 ChatGPTは大学教育のレベルを間違いなく高める――「米国最高の教授」がそう言い切るこれだけの理由
<ChatGPTは教育にとって脅威どころか、大学にとっては逆にプラス。「米国最高の教授」の1人であるサム・ポトリッキオが語る、目からうろこの理由とは>
対話型人工知能(AI)「チャットGPT」が登場したとき、大学教員の間でパニックが広がったが、私は逆に祝杯を挙げた。
対話型人工知能(AI)「チャットGPT」が登場したとき、大学教員の間でパニックが広がったが、私は逆に祝杯を挙げた。

20230405 東大生や教員は生成AIにどう対応すべきか
インターネットなどにある既存の文章や画像データを大量に機械学習し、強化学習と組み合わせて一定レベルの文章や画像を生成する生成AI(人工知能)は、多数の企業が研究や開発を加速している。

20230405 「ルビコン川を渡ってしまった」東京大学が生成系AIに対する声明を発表 | Ledge.ai
東京大学は4月3日、同大のポータルサイトにて理事・副学長である太田 邦史氏の名前で生成系AI(ChatGPT, BingAI, Bard, Midjourney, Stable Diffusionなど)に関する声明文を発表した。 特にOpen AIが開発した対話型AIであるChatGPTを中心に話が展開されて

20230405 「プログラミングは深く学ばなくてOK」今こそ必要な“文系AI人材” 求められる能力とは | 経済・IT | ABEMA TIMES | アベマタイムズ
「ChatGPT」をはじめ、AIの発展と普及が目覚ましい現代社会。AIというと “理系”のイメージが強く、いかにも難しそうだと思う人も多いかもしれない。しかし、そんな時代だからこそ「将来必要とされるのは“AIに強い文系”だ」と提唱する専門家がいる。【映…
20230407 文科省がChatGPTなどの学校現場での取り扱いを示す資料作成へ
2023年4月6日、文部科学省が、AIを使ったソフトウェアの学校現場での取り扱いを示す資料を作成する方針であることが、同日行われた松野博一官房長官の記者会見で明らかになった。ChatGPTをはじめとするAIを用いたソフトウェアの影響力が読書感想文やリポートなど学習にも及ぶことから、国内外の事例を集め、専門家の意見も聞いたうえで、なるべく早く示したいとしている。
20230409 教育・情報担当理事 声明でChatGPTなど生成系AIへの向き合い方を提示
東大の太田邦史理事・副学長(教育・情報担当)は4月3日、オンライン授業やウェブ会議の情報を集積したポータルサイト(utelecon)でChat GPTなど生成系AIに学生や教員がどう向き合うべきかを盛り込んだ発表を行った。技術発展に対し、傍観や拒絶ではなく積極的な態度を取るよう呼び掛けている。今後、生成系AIの活用法や問題点、改善策について議論の機会を作る予定だという。
20230410 対話式AI 国内の大学で利用基準提示や注意喚起の動きも
対話式AIの「ChatGPT」などに関して教育や勉学にさまざまな影響が及ぶとみられることから、国内の大学では、利用の基準を示したり、注意喚起を行うところも出てきています。

20230410 ChatGPTなどの生成系AI、学生の利用について各大学が指針を発表 | Ledge.ai
UnsplashのLevart_Photographerが撮影した写真 国内の大学が、質問に応じて自然な文章を作成するAI「ChatGPT」を巡って、対策に乗り出している。リポートでの利用を制限するなどの動きが広がり、専門家からは教員側の十分な対応が求められている。また、情報流出の危険性についても学生に注意喚
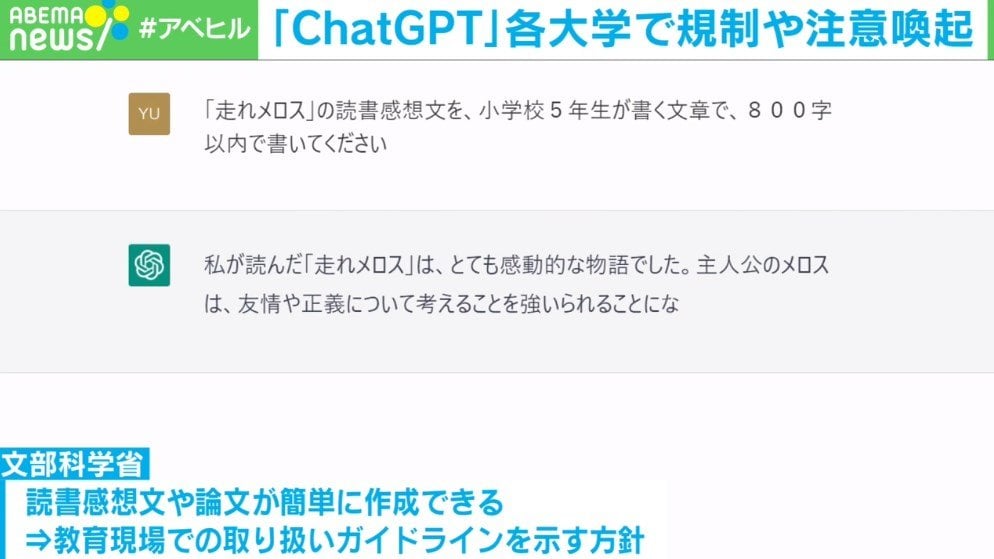
20230410 ChatGPT「上智大:レポート等で原則使用禁止 処分も」「東大:AIのみを用いた論文禁止」大学で規制・注意喚起相次ぐ | 経済・IT | ABEMA TIMES | アベマタイムズ
「ChatGPT」などの便利なAI技術が次々と登場するなか、教育現場でもそうした最新技術とどう向き合うかが問われている。各大学では規制や注意喚起など、学生の使用を見据えた対応がはじまっている。【映像】東大、東北大、上智大のChatGPT対策 松野官房長官…

20230411 対話型AI、大学が規制
「チャットGPT」など人工知能(AI)を使った対話型ソフトを巡り、東大や上智大など一部大学で学生のリポートや論文作成での利用に注意を促す動きが出ていることが11日、分かった。著作権や誤情報への警告にとどまらず「使用を認めない」と明示するケースも。一方で情報ツールとして使いこなすために授業での活用を
20230411 対話型AI、大学が規制 論文利用に警告、思考力懸念
「チャットGPT」など人工知能(AI)を使った対話型ソフトを巡り、東大や上智大など一部大学で学生のリポートや論文作成での利用に注意を促す動きが出ていることが11日、分かった。著作権や誤情報への警告にとどまらず「使用を認めない」と明示するケースも。一方で情報ツールとして使いこなすために授業での活用を検討する大学が登場している。

20230412 翻訳も資料探しもできてしまうChatGPT 英語学習がなくなる?:朝日新聞デジタル
アドバイスや資料を求めれば、世界中のインターネット空間から資料を探し、日本語に翻訳して答えてくれる「ChatGPT(チャットGPT)」。機械翻訳のアプリも進化し、あらゆる言語をリアルタイムで翻訳して…
20230412 ChatGPTで揺れる教育、アカデミアはどう動くか
対話型AI「ChatGPT」を始めとする生成系AIに対して、アカデミアが続々と対応を示し始めている。
ChatGPTが生成する文章には嘘が混じること(hallucination)や、個人情報や機密情報を入力すると漏洩する危険性などが指摘されているが、中でも、学生がChatGPTを使用してレポートや論文を執筆することに対しては、学生の学習効果への影響が懸念され、議論が巻き起こっている。大学間でも対応が分かれており、まだまだ議論は尽きそうにない印象だ。
ChatGPTが生成する文章には嘘が混じること(hallucination)や、個人情報や機密情報を入力すると漏洩する危険性などが指摘されているが、中でも、学生がChatGPTを使用してレポートや論文を執筆することに対しては、学生の学習効果への影響が懸念され、議論が巻き起こっている。大学間でも対応が分かれており、まだまだ議論は尽きそうにない印象だ。
20230413 新学期、ChatGPTへの各大学の方針と反響を総点検!
対話型AI「ChatGPT」を始めとする生成系AIに対して、アカデミアが続々と対応を示し始めている。
ChatGPTが生成する文章には嘘が混じること(hallucination)や、個人情報や機密情報を入力すると漏洩する危険性などが指摘されているが、中でも、学生がChatGPTを使用してレポートや論文を執筆することに対しては、学生の学習効果への影響が懸念され、議論が巻き起こっている。大学間でも対応が分かれており、まだまだ議論は尽きそうにない印象だ。
ChatGPTが生成する文章には嘘が混じること(hallucination)や、個人情報や機密情報を入力すると漏洩する危険性などが指摘されているが、中でも、学生がChatGPTを使用してレポートや論文を執筆することに対しては、学生の学習効果への影響が懸念され、議論が巻き起こっている。大学間でも対応が分かれており、まだまだ議論は尽きそうにない印象だ。

20230413 「日本独自の生成系AIを持つべき」東大副学長の見解が国内外で話題 | 経済・IT | ABEMA TIMES | アベマタイムズ
「ChatGPT」など画像や文章を生成することができる“生成系AI”が飛躍的進化を遂げる一方、学習への影響など様々な問題が指摘されている。そんななか、東京大学が学生や教職員が生成系AIにどう向き合うべきか見解を発表した。【映像】生成系AIとどう向き合…

20230417 教育ネット、「学校でAIを活用するためのChatGPTガイド」を無料配布
株式会社教育ネットは、冊子「学校でAIを活用するためのChatGPTガイド」を教職員向けに無料ダウンロードで公開した。
20230417 対話型AIを小学校の授業に 北教大セミナーで実践報告
北海道教育大学は16日、「ChatGPT」をはじめとする対話型AIの活用などを主題とした公開セミナーを開いた。この中で小学校教員の中村亮太さんは、擬音語などのオノマトペを対話型AIに作らせる授業実践

20230418 AIと人間の「まね」は同じか AIの著作権侵害、弁護士が解説:朝日新聞デジタル
対話型AI(人工知能)「ChatGPT(チャットGPT)」が注目を集めるなか、画像生成AIの開発企業に作品を勝手に使われたとして、米国のアーティストらが訴訟を起こした。判決次第では、世界のクリエータ…

20230418 全国初チャットGPTを試験導入
神奈川県横須賀市は18日、対話型人工知能(AI)「チャットGPT」を20日から業務に試験導入すると発表した。正規職員と非常勤職員の一部の計約4千人が、約1カ月間利用できるようにする。市によると、チャットGPTを全庁で試験導入するのは全国の自治体で初めて。 市職員が既に業務で使用し

20230418 チャットGPT対応急ぐ 規制と活用、バランス模索―リポート、論文作成で・東大など:時事ドットコム
「チャットGPT」をはじめとした対話型人工知能(AI)の急速な普及を受け、一部の大学は教育上の利用について対策を取り始めた。新技術を使ったリポートや論文作成を禁止、制限する方針が目立つ一方で、活用を模索する姿勢も見られた。

20230418 進化するChatGPT、大学のつきあい方は? 情報研所長に聞く:朝日新聞デジタル
問いに対して、なめらかに答えてくれる対話型AI(人工知能)の「ChatGPT(チャットGPT)」が話題をさらっています。大学などでどう活用したらいいのか、課題はなにか。AIの専門家で、4月に国立情報…

20230418 ChatGPT「傍観しないで」 東大副学長が使って感じた創造性:朝日新聞デジタル
東京大学の構成員は変化を傍観するだけでなく、先取りして――。東大が今月3日、「ChatGPT(チャットGPT)」などの生成AI(人工知能)への向き合い方を示した声明が話題となりました。海外では使用禁…

20230419 「データサイエンス・AI全学教育機構設置記念シンポジウム」を開催
東京工業大学 データサイエンス・AI全学教育機構(以下、DSAI全学教育機構)は3月13日、「データサイエンス・AI全学教育機構設置記念シンポジウム」を大岡山キャンパスにてハイブリッド形式で開催しました。 シンポジウムの様子 DSAI全学教育機構は、今日のデジタル情報化社会において大きな役割を担うデータサイエンスや人工知能(以下、DS・AI)の技術を学び、駆使できる人材、さらには専門分野の垣根…

20230420 ChatGPTでリポートは不正? 東大、京大、上智など続々と見解:朝日新聞デジタル
質問や指示に対してなめらかな文章で返答する対話型AI(人工知能)「ChatGPT(チャットGPT)」など生成AIについて、大学が対応を迫られている。AIが書いた文章と学生が執筆した文章とを見分けるの…

20230420 ChatGPT排除は「非現実的」 頭ひねる大学、学生がAI添削も:朝日新聞デジタル
ChatGPT(チャットGPT)などの生成AIを、学生の一部はさまざまに使いこなしている。海外では制限する大学もあるが、大学側が学生に注意点を示しながら、教え方を工夫して活用する姿勢が主流だ。学生に…

20230420 生成AIの祝辞「空虚だがもっともらしい」 名大総長が語る危機感:朝日新聞デジタル
ネット上の情報を学習してなめらかな文章で答えてくれる「ChatGPT(チャットGPT)」などの人工知能(AI)が、大学教育を揺るがしている。名古屋大の杉山直総長(61)は3月の卒業式の祝辞で、「任せ…

20230420 チャットGPT 静岡県内教育界も関心 利便性期待/思考力低下懸念|あなたの静岡新聞
膨大なデータを学習し、質問や依頼に対して人間が答えているような文章などを提供するプログラム「チャットGPT」。これらの生成AI(人工知能)に対し、静岡県内の教育…
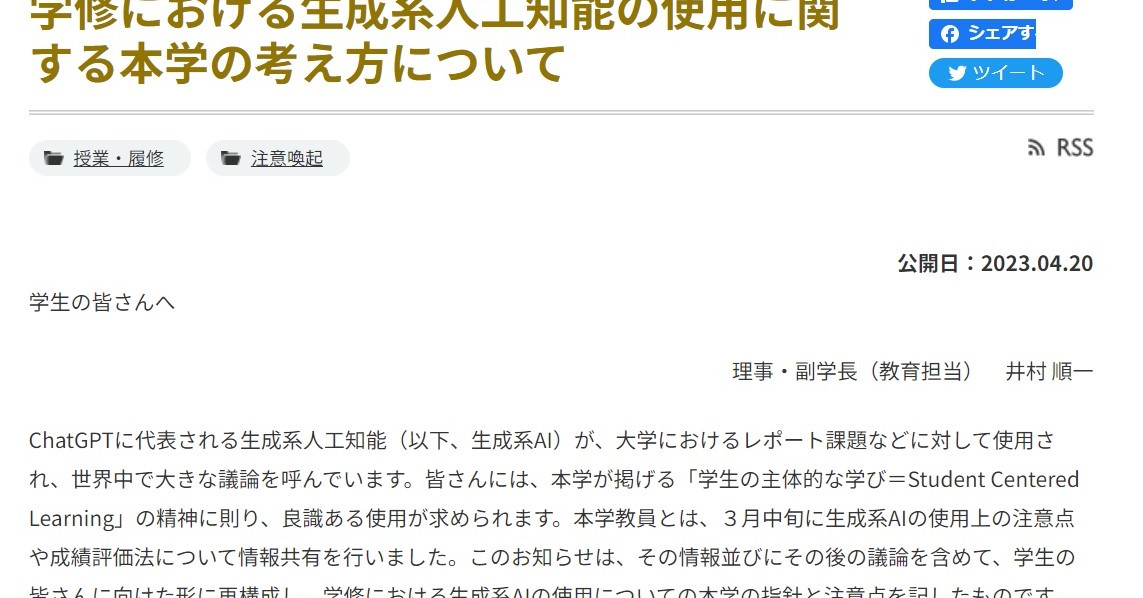
20230421 東工大、ChatGPTなどのAIは「全面禁止しない」 学生の主体性を信頼
東京工業大学が、ChatGPTをはじめたとしたチャットAIの利用について、学生向けの指針を示した。全面禁止にはせず、授業ごとに利用の程度を定めるという。
20230421 チャットGPT 6大学が学生に見解・指針 毎日新聞アンケなど
急速に活用が広がる「ChatGPT(チャットGPT)」など対話型AI(人工知能)について、東京、大阪、九州、上智、青山学院、関西学院の6大学が学生向けに見解・指針を示していたことが毎日新聞のアンケートなどで判明した。

20230421 対話AI利用、大学模索 リポートには制限/情報整理に期待:朝日新聞デジタル
質問や指示に対してなめらかな文章で返答する対話型AI(人工知能)「ChatGPT(チャットGPT)」など生成AIについて、大学が対応を迫られている。AIが書いた文章と学生が執筆した文章とを見分けるの…

20230421 自己分析して学校探検も、新中1が始業プログラム…星の杜
【読売新聞】 星の杜中学校・高等学校(宇都宮市)の新中学1年生は4月10日から、授業開始に向けた準備プログラムに取り組みました。オンラインツール「Ai GROW(アイ グロー)」で自分の性格などを分析。また、ミッションスクールなどに

20230422 ChatGPTの急拡大「新技術の練習問題に」 阪大が課題を整理:朝日新聞デジタル
対話型AI(人工知能)「ChatGPT(チャットGPT)」などの生成AIの活用が急速に広がっている。どのように使いこなし、制限をかけるべきなのはどんな場合か。そんなつきあい方を考えるための基礎資料と…
20230423 チャットGPT利用どうやって見抜くか 東北の大学、企業に「生成AI」対応の動き
対話型人工知能(AI)の「チャットGPT」で注目が集まる生成AIを巡り、対応を検討する動きが東北の大学や企業などで広がりつつある。生成された文章が本人のものかどうか確認しにくいためだ。安易な利用の弊害が指摘される一方、新たな成果を期待する声もあり、現場でルールづくりの模索がしばらく続きそうだ。

20230424 山梨英和高 授業にAI活用 | さんにちEye 山梨日日新聞電子版
山梨日日新聞のホームページです。山梨県内外の最新ニュースや朝刊紙面、スポーツ速報など知りたい情報が満載。スマートフォン/タブレット/パソコンで読むことができます。

20230424 「生成AI使うだけでは学びは深まらない」大阪大学が生成AI利用についての声明を発表 | Ledge.ai
大阪大学は2023年4月17日に、生成AI(Generative AI)の利用についての声明を発表した。 生成AI利用についての声明の要約 ChatGPTのような自然言語AIチャットボットなどが、質問に応じて自然言語やプログラムコード、画像などを生成できるようになった。これらを適切に使うことで、効率的な作業を

20230424 愛知大学がAI対話エンジン「PKSHA Chatbot(パークシャチャットボット)」を導入、東海エリア教育機関で初
パークシャテクノロジーのプレスリリース(2023年4月24日 15時30分)愛知大学がAI対話エンジン[PKSHA Chatbot(パークシャチャットボット)]を導入、東海エリア教育機関で初

20230424 「ChatGPTの利用前提に全てを見直す方向へかじを切る」、東京大学の太田副学長
「ChatGPT」などの生成系AI(人工知能)の利用が急速に広がるなか、生成系AIに関する教員や学生向けの文書を学内サイトに掲載した東京大学の太田邦史理事・副学長。発信の真意やChatGPTのような技術への向き合いかたを聞いた。

20230425 教育とAI 思考力の育成を妨げかねない
【読売新聞】 高い能力を持つ人工知能(AI)の登場に、教育現場が揺れている。人間の思考を代替させるような使い方は、極めて問題が大きい。ルールづくりを急がねばならない。 米新興企業が開発した対話型AI「チャットGPT」は、文章中の単語

20230425 「チャットGPT」禁止は非現実的 県内大学が対応模索
対話型人工知能(AI)「チャットGPT」などの学生の利用を巡って、県内の大学が対応を模索している。情報収集などに活用できるが、回答に誤りがあることや個人情報流出が懸念されており、ルールづくりを進める

20230425 立命館大学で英語の授業に「ChatGPT」試験的に導入 |NHK 京都府のニュース
【NHK】対話式のAI、「ChatGPT」を英語の授業で試験的に導入して、表現力の向上につなげようという取り組みが立命館大学で始まりました。 この…

20230426 ChatGPT試験導入 立命館大学の英語授業に|NHK 関西のニュース
【NHK】対話式のAI、「ChatGPT」を英語の授業で試験的に導入する取り組みが立命館大学で始まりました。 この取り組みは、滋賀県草津市にある立…

20230426 「大学教育のAI化」こそ“人への投資”の特効薬だ
ChatGPTの登場で、学生が論文やレポート、試験に使うのを認めるか否か、といった議論がある。しかし、ChatGPTの真の問題は、学生ではなく先生の方にある。ChatGPTは、「人による教育」という作業の多くを不要にする潜在力を持っているからだ。そして、その「大学教育のAI化」こそ“人への投資”の特効薬であり、日本にとって最後に放てる逆転打の可能性なのだ。

20230426 県内大学、対話型AI利用法模索 論文作成「丸写し」事例も
対話型人工知能(AI)「チャットGPT」などの学生の利用を巡って、県内の大学が対応を模索している。情報収集などに活用できるが、回答に誤りがあるこ…

20230426 対話型AIで情報活用の重心は知識基盤へ移行――NII所長 黒橋 禎夫氏インタビュー
国立情報学研究所(NII)所長に就任した黒橋禎夫氏は、言語モデルなどAI(人工知能)を研究してきた。折しも「ChatGPT」が自然な会話で人々を驚かせた今、AI時代の所長としての取り組みを聞いた。

20230427 24年卒学生の約半数、ChatGPTでの選考書類作成は「問題ない」と回答【文化放送キャリアパートナーズ調査】
文化放送キャリアパートナーズは、2024年卒業予定の学生を対象に実施した、「2024年卒ブンナビ学生調査(2023年3月下旬実施)」の結果を4月24日に発表した。同調査は、3月16日~27日の期間に行われ、219名(文系男子:55名、文系女子:76名、理系男子:55名、理系女子:33名)から有効回答を得ている。

20230427 ChatGPTの禁止はナンセンス――東京大学 松尾 豊氏インタビュー
ChatGPTのような生成AIは人間の領域を侵し始めているように見える。東京大学大学院でAIの研究を続け、日本ディープラーニング協会の理事長も務める松尾豊氏に、技術的な限界と教育への影響を聞いた。
/cloudfront-ap-northeast-1.images.arcpublishing.com/sankei/QZNPZMHSN5JX5JVXG65ABH2POA.jpg)