とある教職教科書の執筆にお呼ばれをして、プログラミング教育に関する部分を書きました。
依頼を受けたのは1年以上前でしたが、それ以来、何を取り上げてどう書けば良いだろうか、という宿題が頭の中でずっと渦巻き続け、先日やっと提出し終えたところです。
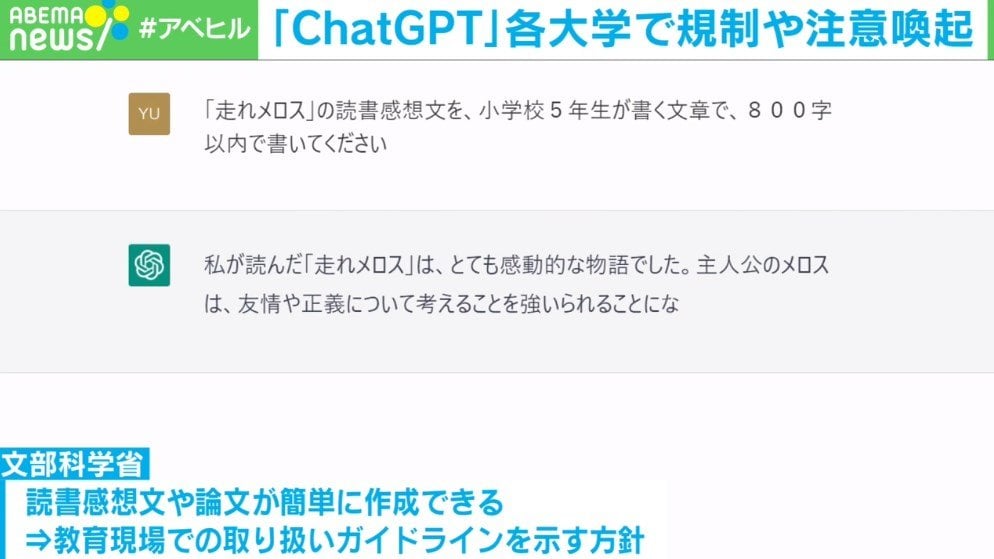
苦労しました。今年に入って生成系AIの騒がれ振りを目の当たりにしたことで、一旦提出した原稿のアップデートを願い出たりもしました。編者の方にも賛同いただき見直し書き直し。
紙数の制約上、いろんな基礎的情報を端折り(たとえば特定のプログラミング言語の言及が皆無)、一方で、撲滅したかった「プログラミング的思考」という表記を幾度か出すという苦渋の選択もありました。もともと執筆依頼のキーワードだったことや文部科学省文書を扱わざるを得ない手前、仕方なし。
それでも、ずっと海外のプログラミング教育やCS教育の文献資料を漁る中で拾った知見に触れたりして、諸外国のプログラミング教育、コンピュータサイエンス(CS)教育と通じ合うための要素も少しは盛り込むことができたのではないかと思います。
もっとも「プログラミング教育」という窮屈な枠組みはオワコンだという雰囲気もありますが。
—
これまで、日本のプログラミング教育の言説は、ほとんどが国の審議や報告書、行政文書の中で紡がれた文言が発祥のものばかりでした。
確かに日本の学校教育はそうしたものに大きく規定されながら運営されているので、それらを無視するわけにはいかないのですが、教職教科書といえども、それを語るときの距離感や姿勢には注意を払わなければなりません。他者の言説を無批判になぞるのは望ましくありません。
今回の原稿は、執筆コンセプトに学習科学や教育工学的な観点が求められていたので、国発信の「手引」の二番煎じをしても意味はなく、その次のステップの糸口を提供できる内容を模索しなければなりませんでした。
その試みが成功したのかどうかは、世に出たときに読んで判断していただければと思います。
—
今回、かなり執筆の時間的猶予を与えていただいたにも関わらず、やはり土壇場まで悩み続けていたことを振り返るにつけ、自分は、すでに誰かが語ったことをどう扱うかについての葛藤を解決するのが上手くないのだなと思い知らされます。
どんなに自らの言葉や考えに昇華したとしても、それを開陳する時点で真似や伝言ゲームをしているだけじゃないかと思えてしまい、ならば原典に当たってもらった方がマシなんじゃないかと思ってしまうからです。
その辺を妥協して、自分なりの言及を付すことで意味ある形に落とし込めればラッキーだし、上手くいかなかったら所詮は横を縦にするコピペ職人なんだろうなと気持ち凹んで過ごすというわけです。
これはつまり、そろそろ私自身の知の貯蓄も尽きてきたといったところかも知れません。
—
理不尽な状況にほとんどの人々が冷めた状態で接することを余儀なくされて、力なく願いだけが積み重ねられていく様子を見せられると、思いを語る意義さえ見失われます。あるいは躊躇われてしまう。
社会全体でこういう無気力の学習が展開していて、あとはオーソライズされた言葉を違和感なく組み合わせていくだけで何かをまとめた気分になるだけ。そこに人を魅了する熱意や欲望みたいなものはないし、いつも待っているのはこんなはずじゃなかった感のある結末。
切り替えていくことに取り組まなければならない。そう思うこの頃です。










































































/cloudfront-ap-northeast-1.images.arcpublishing.com/sankei/QZNPZMHSN5JX5JVXG65ABH2POA.jpg)